TinyML MCU Hardware Guide 2026: NPUs, Memory, Power
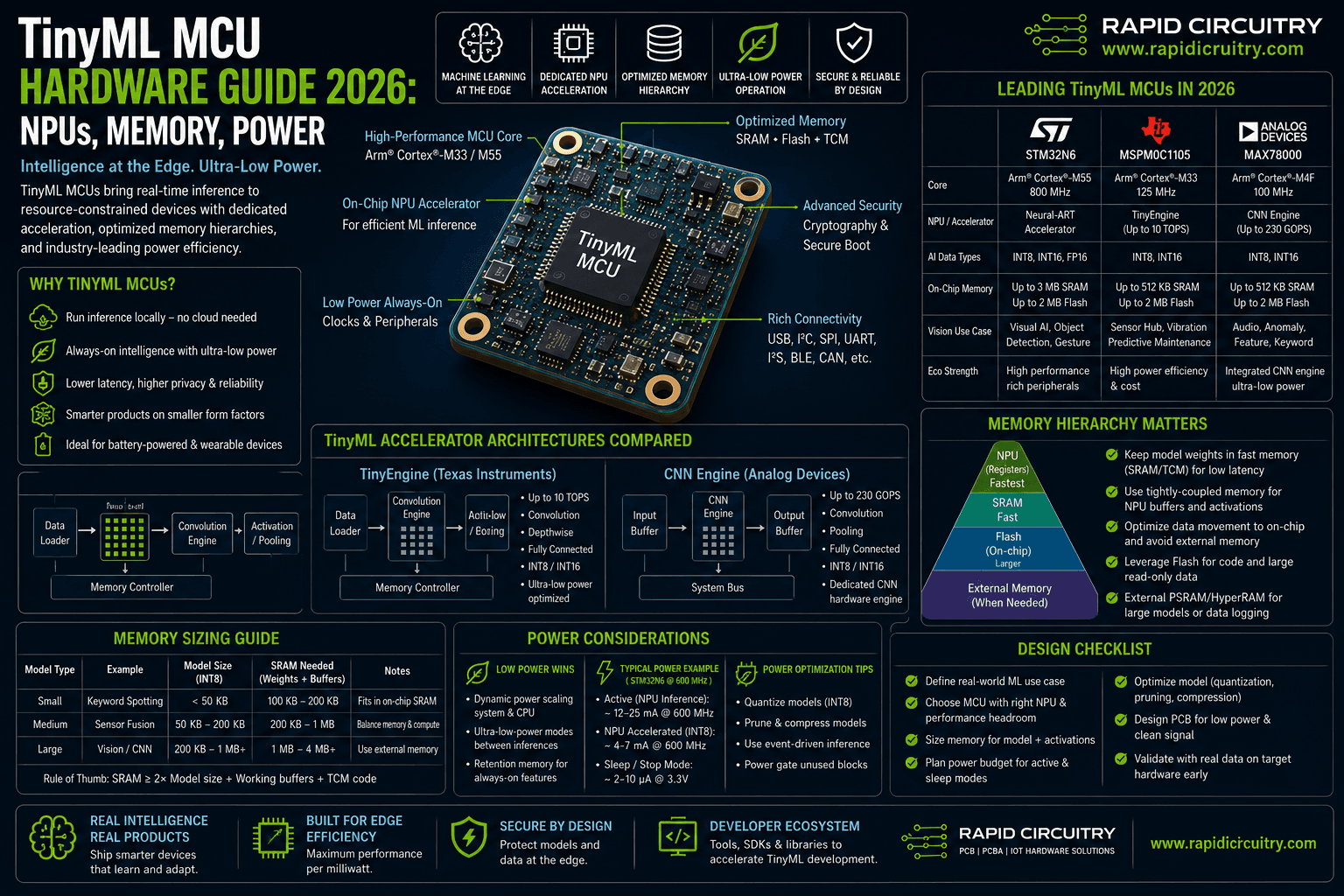
TinyML MCU hardware in 2026 has moved from research curiosity to mainstream specification line item. Three families now dominate engineering shortlists: STMicroelectronics' STM32N6 with its Neural-ART accelerator, Texas Instruments' MSPM0G5187 with TinyEngine NPU, and Analog Devices' MAX78000 with a dedicated convolutional neural network engine. This guide walks through what makes a TinyML MCU different from a general-purpose part, how the accelerator architectures compare, and how to size memory and power for a real workload.
Key Takeaways
- A TinyML MCU pairs a standard CPU core with a dedicated neural network accelerator block, removing inference from the main CPU and cutting both latency and energy.
- NPU peak throughput across the 2026 lineup spans roughly three orders of magnitude: from sub-gigaop figures on small Cortex-M0+ class parts up to 600 GOPS on the STM32N6.
- Memory architecture, not raw TOPS, is usually the deciding factor: model weights, activations, and image buffers must all fit on-chip for the power numbers to hold.
- Quantization to 8-bit, 4-bit, or 2-bit weights is the standard lever for shrinking models to fit MCU SRAM and flash, and modern NPUs support multiple precisions natively.
- Vision, keyword spotting, and sensor anomaly detection are the workload classes that map well to TinyML MCU silicon; large language models and high-resolution video do not.
- The right MCU choice depends on inference rate, model topology, and power budget, in that order. Peak GOPS in the datasheet is misleading without a target workload.
How TinyML MCUs Differ From General-Purpose MCUs
A general-purpose microcontroller runs neural network inference on its CPU using vendor-supplied DSP and CMSIS-NN kernels. That works for very small models, but a 100-kilobyte convolutional network on a Cortex-M4 at 100 MHz can take hundreds of milliseconds per inference and burn most of the energy budget on data movement rather than arithmetic. A TinyML MCU changes the picture by adding a neural network accelerator block to the same die. The accelerator is a fixed-function engine optimized for the multiply-accumulate (MAC) operations that dominate inference, with its own SRAM tightly coupled to the compute fabric.
Accelerator architecture classes
Three accelerator architectures appear across the 2026 lineup. STMicroelectronics' Neural-ART in the STM32N6 is a configurable MAC array clocked at 1 GHz with close to 300 MAC units and a pair of 64-bit AXI memory buses; ST quotes 600 GOPS and an efficiency near 3 TOPS per watt for the block. Analog Devices' MAX78000 uses a hard-wired convolutional engine with 64 parallel processors and dedicated on-chip weight and activation SRAM, optimized for inference at the lowest possible energy per frame. Texas Instruments' MSPM0G5187 takes a different route: TinyEngine is a compact NPU paired with a Cortex-M0+ at 80 MHz, designed to drop into cost-sensitive applications that would otherwise have no AI at all.
What changes for the hardware engineer
For the engineer specifying the board, three things change. First, model storage moves into the design conversation: weight memory and activation buffers compete for the same on-chip SRAM as application state. Second, power profiling shifts from average CPU current to per-inference energy. Third, the choice of CPU core matters less than it used to, since the heaviest compute lives in the accelerator rather than on the core itself.
NPU Architectures in TinyML MCUs
The accelerator block is where the marketing numbers live, but the architecture decides what those numbers mean in practice. Each of the three architectures below trades flexibility, throughput, and energy in a different way.
MAC arrays and dataflow engines
A MAC-array architecture, like Neural-ART, looks closer to a reconfigurable systolic MAC fabric than to a CPU. The engineer configures dataflow paths between MAC units, weight SRAM, and activation SRAM at compile time using the vendor's neural network compiler. The advantage is flexibility: any topology the compiler can map runs at high utilization. The cost is that maximum performance requires a model the compiler can pipeline efficiently, and getting there often means rewriting the model graph to match the accelerator's preferred operator set.
Hard-wired convolution engines
A hard-wired CNN engine like the one in the MAX78000 trades flexibility for efficiency. The 64 parallel processors and the on-chip weight memory are sized around convolutional workloads, which means that fitting a model to the silicon requires care, but the energy per inference becomes very small once it fits. The MAX78000 also includes a RISC-V coprocessor for sensor preprocessing, which keeps the main Cortex-M4 asleep through routine wake-and-classify cycles.
Compact NPUs for cost-sensitive applications
TinyEngine on the MSPM0G5187 is the third pattern: a small NPU that supports 8-bit, 4-bit, and 2-bit weight precisions, attached to a low-cost CPU. The vendor pitch from Texas Instruments is that inference latency drops by up to 90x and energy per inference drops by more than 120x compared with running the same model on the Cortex-M0+ alone. The architecture is sized for keyword spotting, sensor anomaly detection, and small classification networks, not for vision pipelines that push past a few hundred kilobytes of weights.
NPU comparison table
| Platform | CPU core | NPU peak throughput | Weight precisions | Typical workload class |
|---|---|---|---|---|
| STM32N6 (ST) | Arm Cortex-M55 @ 800 MHz | 600 GOPS @ 1 GHz, ~3 TOPS/W | 8-bit and mixed | Vision, multi-modal |
| MAX78000 (Analog Devices) | Arm Cortex-M4 + RISC-V coprocessor | 64 parallel CNN processors | 1, 2, 4, 8-bit | Always-on audio, low-res vision |
| MSPM0G5187 (TI) | Arm Cortex-M0+ @ 80 MHz | Compact TinyEngine NPU | 2, 4, 8-bit | Keyword spotting, sensor inference |
The peak numbers do not translate directly into application performance. A model that fits comfortably in MAX78000 weight memory may exceed the practical SRAM budget on the MSPM0G5187, and a vision pipeline that runs at a useful frame rate on the STM32N6 may be impossible to deploy on either of the other two.
Memory Architecture for TinyML Workloads
Memory is the constraint that usually decides a TinyML MCU selection, and the discussion below is best read with the platform datasheets in hand.
Model storage and weight access
Per the Analog Devices datasheet, the MAX78000 dedicates 442 KB of SRAM to weight storage inside the CNN engine, supporting up to roughly 3.5 million parameters at low bit-widths. The STM32N6 has access to the full STM32 memory hierarchy, including external octo-SPI memory and on-chip SRAM measured in megabytes, which lets it run substantially larger vision models. The MSPM0G5187 ships with 128 KB of flash and 32 KB of SRAM, including 8 KB of data flash, which sets a hard ceiling on model size.
Weight storage in SRAM rather than flash is what lets accelerators sustain high throughput. Flash read latency is high enough that MAC arrays starve waiting for weights, so the dominant pattern is to keep the weight working set in SRAM tightly coupled to the engine and stream from flash only at model load.
Activation memory budgets
Activations are the intermediate feature maps produced layer by layer. On a vision model with 96x96 input, a single activation tensor at 16 channels and 8-bit per sample is already 144 KB before any pooling. On an MCU-class device, fitting activations on chip usually drives the input resolution down, the use of depthwise separable convolutions up, and the use of in-place activation buffers wherever the topology permits.
Data flash and OTA model updates
Storing weights in dedicated data flash separates application code from model code and supports over-the-air model updates without re-flashing firmware. The MSPM0G5187's 8 KB data flash is small but enough for parameter sets in compact deployments; the MAX78000's SRAM-based weight memory lets the model change at runtime from external storage; the STM32N6 supports the largest model footprints by mapping weights through external memory if needed.
Power Profiles and Energy Per Inference
Average current numbers in datasheets are a starting point, not an answer. The figure of merit for this hardware is energy per inference at a target accuracy.
Always-on inference patterns
Always-on keyword spotting and presence detection workloads run at fixed inference rates measured in inferences per second, with the CPU asleep in between. Analog Devices' launch materials for the MAX78000 cite per-inference energies as low as the single-digit microjoule range for the smallest demonstrated keyword-spotting networks, which puts year-long battery life in scope for small primary cells given a modest duty cycle.
Duty cycling and wake-on-event
Vision and higher-resolution audio workloads cannot run continuously on a coin cell. The standard pattern is wake-on-event: a low-power analog front end or a low-resolution sensor triggers the NPU only when something interesting happens. The STM32N6 fits this profile when paired with a sensor that produces a low-bandwidth wake signal; the high TOPS budget pays off when activated rarely.
Power integrity considerations
NPU current draw is bursty: a single inference may pull tens or hundreds of milliamps for a few milliseconds while idle current is in the microamp range. The bypass capacitor network around the MCU must handle that transient without sagging the supply rail. Boards that placed a single bulk capacitor near the regulator and trusted via inductance to handle the rest will show timing failures or clock recovery glitches under load. For higher-current parts like the STM32N6, the same power-integrity discipline that applies to a fast FPGA core rail applies to the MCU rail.
Selecting a TinyML MCU for Your Workload
The selection sequence that holds up in real projects is workload first, memory second, power third. Each platform below covers a different region of that design space.
Vision
For 96x96 to 224x224 input images, full convolutional networks, and useful frame rates, the STM32N6 is the natural target in this lineup. The Neural-ART throughput, the larger memory hierarchy, and ST's neural network compiler ecosystem all point at this class of workload.
Audio and keyword spotting
For wake-word detection, keyword spotting, and short audio classification, the MAX78000 and the MSPM0G5187 are both viable. The MAX78000 wins on energy per inference; the MSPM0G5187 wins on system cost and integration with TI's existing MSPM0 ecosystem.
Sensor fusion and anomaly detection
For accelerometer, vibration, and time-series workloads, small fully-connected and recurrent models fit comfortably on the MSPM0G5187 and enable predictive maintenance and condition monitoring workloads that previously required either an external DSP or a cloud connection.
Practical Implications for Hardware Teams
- Set the model topology and accuracy target before selecting the MCU. Hardware that is overkill for the chosen network wastes BOM cost; hardware that is undersized cannot host the model at the required accuracy.
- Profile energy per inference on real silicon early. Datasheet numbers are best case and rarely include the supporting analog chain.
- Reserve flash and SRAM headroom for model updates. A model that fits exactly today will not fit tomorrow when retrained on more data.
- Lay out the supply network for bursty NPU current. Treat the NPU rail as a small mixed-signal core rail rather than as a general MCU rail.
- Add a test point for the inference trigger signal. Energy-per-inference measurement and tuning depend on aligning a current probe with a clean trigger.
- Keep the option to move to a host processor open. If the model grows past what the MCU can hold, the same firmware design should port to a Cortex-A SoC with minimal application rework.
Common Questions About TinyML MCUs
What is the difference between a TinyML MCU and a standard MCU?
A TinyML MCU integrates a dedicated neural network accelerator alongside a conventional CPU core, with on-chip SRAM sized for model weights and activations. A standard MCU runs inference on the CPU using software libraries, which costs significantly more energy and time for the same model.
How much flash and RAM does a TinyML model need?
Practical models in 2026 range from a few kilobytes for keyword spotting on the MSPM0G5187 up to several hundred kilobytes of weights for vision models on the STM32N6 and MAX78000. Quantization to 8-bit, 4-bit, or 2-bit weights is what makes those numbers practical.
Can you run vision models on an MCU?
Yes, within constraints. Input resolutions of 96x96 to 224x224, low channel counts, and depthwise-separable convolutional topologies are typical. Full-color, high-resolution networks like those used on smartphones do not fit and run on application processors instead.
What frameworks support TinyML deployment in 2026?
TensorFlow Lite for Microcontrollers, ONNX Runtime, and vendor-specific compilers (STM32Cube.AI for ST, the MAX78000 synthesis flow for Analog Devices, and TI's TinyEngine flow) all see active use. Most projects converge on the vendor compiler for production builds because the hardware-specific optimizations matter.
How does NPU energy efficiency compare with CPU-only inference?
The vendor-reported gap is roughly two orders of magnitude. TI quotes up to 90x latency reduction and 120x energy reduction on the MSPM0G5187 versus running the same model on the Cortex-M0+. Real numbers depend on the model and the comparison baseline, but the order of magnitude is consistent across the lineup.
Is RISC-V or Arm Cortex-M better for a TinyML MCU?
For the accelerator-class parts covered here, the choice of CPU core is secondary because the heavy compute lives in the NPU. RISC-V is gaining ground in the MCU market in 2026, including as a coprocessor inside the MAX78000, but the CPU core selection is rarely the deciding factor for a TinyML deployment.
Working With Rapid Circuitry on TinyML MCU Designs
A TinyML MCU deployment lives or dies on the interaction between the model, the silicon, and the board around it. Rapid Circuitry's hardware team works through the same selection sequence on customer projects: define the workload, size the memory, model the energy budget, and only then commit to a footprint and stackup. If you are weighing a TinyML MCU for a new product, reach out to discuss the architecture and we can help you down-select before you commit a board spin to it. For related background, see our edge AI PCB design guide and the RISC-V MCU selection guide for context on the wider edge AI hardware picture.
Need help with edge computing & ai hardware?
Get a free consultation with our expert engineers. We respond within 24 hours.
Get a Free ConsultationStill researching? Read our free How to Choose a Microcontroller (MCU).
Stay in the Loop
Subscribe to our newsletter for the latest updates and insights.
By subscribing, you agree to our Privacy Policy. You can unsubscribe at any time.